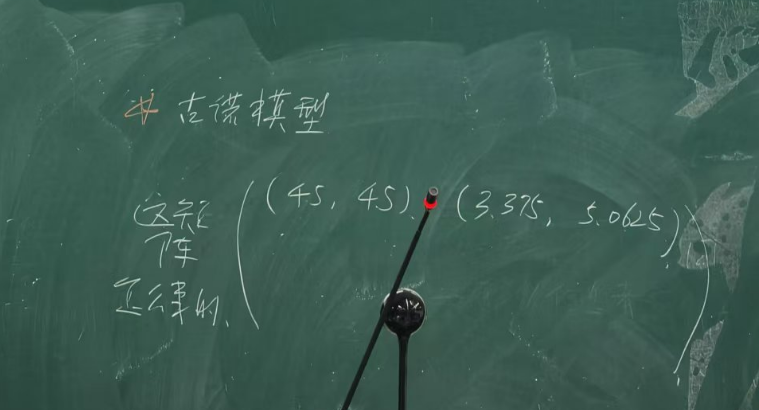11.20,第12周周三,晚 5:50-7:50,带有照片证件
基本概念
静态博弈、动态博弈、完全(不完全)信息、完美(不完美)信息
纳什均衡、逆向选择、道德风险
海萨尼转换
信号传递、信号甄别
基本方法
收益矩阵分析
博弈树分析
单一价格旧车模型:一个饭店推出高价外卖
委托代理模型:代理的努力程度与工作结果关系不确定、且委托无法监督代理的努力程度
求贴现率 δ \delta δ
求效率工资 W ∗ W^* W ∗
古诺模型
静态博弈和动态博弈的分类取决于人们讨论这类问题使用的方法,而不是目标对象的运动状态。人们用静态方法讨论问题,则为静态博弈;否则为动态博弈。
静态博弈:如一博弈中,每个局中人都只有一次行为机会,且他们在信息意义下(行为前不能观测他人的行为)
动态博弈:如一博弈中,一些局中人有不只一次的行为机会,或有些局中人能在行为前预测到一些他人的行为
如一博弈中,一局中人对各种策略组合下各局中人的收益都完全了解,则称这局中人有完全信息
如一博弈中,一局中人对有些策略组合下有些局中人的收益不完全了解,则称这局中人有不完全信息
完全信息博弈:每一局中人都有完全信息
不完全信息博弈:有一局中人有不完全信息
便士博弈下,双方都有完全信息。博弈论的任务,预测哪个策略组合出现。
动态博弈中,轮到行为的局中人对此前已行为的局中人的所有行为能完全观测, 则称这局中人有完美信息
动态博弈中,轮到行为的局中人对此前已行为的有些局中人的行为不能完全观测,则称这局中人有不完美信息
行为只看完美(不完美)
收益只看完全(不完全)
一博弈中,如存在一策略组合,单个局中人独自离开策略组合(选择其他策略组合而不是离开博弈),其收益不会增加,则称这策略组合为这一博弈的纳什均衡
对某个对象(事物、问题),双方知道的一样多,则称为信息对称;一方知道的多,一方知道的少,则称为信息不对称
信息不对称发生在签约前或交易前,称为事前信息不对称
研究事前信息不对称的理论或模型称为逆向选择
研究事后信息不对称的理论或模型称为道德风险
旧车模型:好车离开市场,差车留在市场,市场让差车留下,即市场选择了差车。
引进虚拟局中人,将虚拟局中人决定私有信息局中人的类型作为博弈的第一阶段,再进行原博弈。将对有私人信息局中人类型的不了解转换为对虚拟局中人行为的不了解,将不完全信息转换为不完美信息
有私人信息局中人的先行为模型称为信号传递
有私人信息局中人的后行为模型称为信号甄别
1 求职者,2 雇主
信号传递
“自然”确定求职者能力“强”“弱” —— 海萨尼转换
求职者选定受教育水平 —— 有私人信息局中人先行为 两雇主各定与受教育水平及工作效果有关的合同 求职者接受一合同或拒绝所有的合同
结果
信号甄别
“自然”确定求职者能力“强”“弱” —— 海萨尼转换
两雇主各定与受教育水平及工作效果有关的合同 求职者选择受教育水平 —— 有私人信息局中人后行为 求职者接受一合同或拒绝所有的合同
结果
不合作
π 1 = q 1 ( 8 − ( q 1 + q 2 ) ) − q 1 2 π 2 = q 2 ( 8 − ( q 1 + q 2 ) ) − q 2 2 ↓ ∂ π 1 ∂ q 1 = 0 , ∂ π 2 ∂ q 2 = 0 ↓ 6 − 2 q 1 − q 2 = 0 , 6 − 2 q 2 − q 1 = 0 ↓ q 1 = 6 − q 2 2 , q 2 = 6 − q 1 2 ↓ q 1 = q 2 = 2 ↓ π 1 = π 2 = 4 \pi_1=q_1(8-(q_1+q_2))-q_12\\
\pi_2=q_2(8-(q_1+q_2))-q_22\\
\downarrow\\
\frac{\partial\pi_1}{\partial q_1}=0,\frac{\partial\pi_2}{\partial q_2}=0\\
\downarrow\\
6-2q_1-q_2=0,6-2q_2-q_1=0\\
\downarrow\\
q_1=\frac{6-q_2}{2},q_2=\frac{6-q_1}{2}\\
\downarrow\\
q_1=q_2=2\\
\downarrow\\
\pi_1=\pi_2=4 π 1 = q 1 ( 8 − ( q 1 + q 2 )) − q 1 2 π 2 = q 2 ( 8 − ( q 1 + q 2 )) − q 2 2 ↓ ∂ q 1 ∂ π 1 = 0 , ∂ q 2 ∂ π 2 = 0 ↓ 6 − 2 q 1 − q 2 = 0 , 6 − 2 q 2 − q 1 = 0 ↓ q 1 = 2 6 − q 2 , q 2 = 2 6 − q 1 ↓ q 1 = q 2 = 2 ↓ π 1 = π 2 = 4 合作
π = q ( 8 − q ) − q 2 = 6 q − q 2 ↓ ∂ π ∂ q = 6 − 2 q ↓ q = 3 , q 1 = q 2 = 1.5 ↓ π = 9 , π 1 = π 2 = 4.5 \pi=q(8-q)-q2=6q-q^2\\
\downarrow\\
\frac{\partial\pi}{\partial q}=6-2q\\
\downarrow\\
q=3,q_1=q_2=1.5\\
\downarrow\\
\pi=9,\pi_1=\pi_2=4.5 π = q ( 8 − q ) − q 2 = 6 q − q 2 ↓ ∂ q ∂ π = 6 − 2 q ↓ q = 3 , q 1 = q 2 = 1.5 ↓ π = 9 , π 1 = π 2 = 4.5 合作但背叛
π 2 = q 2 ( 8 − ( q 2 + 1.5 ) ) − q 2 2 = 4.5 q 2 − q 2 2 ↓ ∂ π 2 ∂ q 2 = 4.5 − 2 q 2 ↓ q 1 = 1.5 , q 2 = 2.25 ↓ π 2 = 5.0625 , π 1 = 1.5 ( 8 − ( 1.5 + 2.25 ) ) − 3 = 3.375 \pi_2=q_2(8-(q_2+1.5))-q_22=4.5q_2-q_2^2\\
\downarrow\\
\frac{\partial\pi_2}{\partial q_2}=4.5-2q_2\\
\downarrow\\
q_1=1.5,q_2=2.25\\
\downarrow\\
\pi_2=5.0625,\pi_1=1.5(8-(1.5+2.25))-3=3.375 π 2 = q 2 ( 8 − ( q 2 + 1.5 )) − q 2 2 = 4.5 q 2 − q 2 2 ↓ ∂ q 2 ∂ π 2 = 4.5 − 2 q 2 ↓ q 1 = 1.5 , q 2 = 2.25 ↓ π 2 = 5.0625 , π 1 = 1.5 ( 8 − ( 1.5 + 2.25 )) − 3 = 3.375 最终得到的收益矩阵
[ 合作 不合作 合作 ( 4.5 , 4.5 ) ( 3.375 , 5.0625 ) 不合作 ( 5.0625 , 3.375 ) ( 4 , 4 ) ] \begin{bmatrix}
& 合作 & 不合作 \\
合作 & (4.5,4.5) & (3.375,5.0625) \\
不合作 & (5.0625,3.375) & (4,4) \\
\end{bmatrix} 合作 不合作 合作 ( 4.5 , 4.5 ) ( 5.0625 , 3.375 ) 不合作 ( 3.375 , 5.0625 ) ( 4 , 4 ) graph
A[甲] -->|合作| B[乙]
A -->|不合作| C[乙]
C -->|不合作| D["(4,4)"]
[ 合作 不合作 合作 ( 4.5 , 4.5 ) ( 3.375 , 5.0625 ) 不合作 ( 5.0625 , 3.375 ) ( 4 , 4 ) ] \begin{bmatrix}
& 合作 & 不合作 \\
合作 & (4.5,4.5) & (3.375,5.0625)\\
不合作 & (5.0625,3.375) & (4,4)
\end{bmatrix} 合作 不合作 合作 ( 4.5 , 4.5 ) ( 5.0625 , 3.375 ) 不合作 ( 3.375 , 5.0625 ) ( 4 , 4 ) 如果选择合作
P V = [ 4.5 , 4.5 δ , 4.5 δ 2 , … , 4.5 δ n − 1 ] ↓ T P V = 4.5 1 − δ PV=[4.5,4.5\delta,4.5\delta^2,\dots,4.5\delta^{n-1}]\\
\downarrow\\
TPV=\frac{4.5}{1-\delta} P V = [ 4.5 , 4.5 δ , 4.5 δ 2 , … , 4.5 δ n − 1 ] ↓ TP V = 1 − δ 4.5 如果选择不合作
P V = [ 5.0625 , 4 δ , 4 δ 2 , … , 4 δ n − 1 ] ↓ T P V = 5.0625 + 4 ( δ − δ n ) 1 − δ = 5.0625 + 4 δ 1 − δ PV=[5.0625,4\delta,4\delta^2,\dots,4\delta^{n-1}]\\
\downarrow\\
TPV=5.0625+\frac{4(\delta-\delta^{n})}{1-\delta}=5.0625+\frac{4\delta}{1-\delta} P V = [ 5.0625 , 4 δ , 4 δ 2 , … , 4 δ n − 1 ] ↓ TP V = 5.0625 + 1 − δ 4 ( δ − δ n ) = 5.0625 + 1 − δ 4 δ 如果合作的总现值大于不合作的总现值,选择合作
4.5 1 − δ > 5.0625 + 4 δ 1 − δ 4.5 > 5.0625 − 5.0625 δ + 4 δ 1.0625 δ > 0.5625 δ > 0.5625 1.0625 = 9 17 \frac{4.5}{1-\delta}\gt 5.0625+\frac{4\delta}{1-\delta}\\
4.5\gt 5.0625-5.0625\delta+4\delta\\
1.0625\delta\gt0.5625\\
\delta\gt\frac{0.5625}{1.0625}=\frac{9}{17} 1 − δ 4.5 > 5.0625 + 1 − δ 4 δ 4.5 > 5.0625 − 5.0625 δ + 4 δ 1.0625 δ > 0.5625 δ > 1.0625 0.5625 = 17 9 当 δ > 9 17 \delta\gt\frac{9}{17} δ > 17 9
如果选择不合作,也就是 δ < 9 17 \delta\lt\frac{9}{17} δ < 17 9
各产产量 d d d 1.5 < d < 2 1.5\lt d\lt 2 1.5 < d < 2
π 1 = π 2 = d ( 8 − 2 d ) − 2 d = − 2 d 2 + 6 d \pi_1=\pi_2=d(8-2d)-2d=-2d^2+6d π 1 = π 2 = d ( 8 − 2 d ) − 2 d = − 2 d 2 + 6 d
一人产 d d d q 2 q_2 q 2
π 2 = q 2 ( 8 − ( d + q 2 ) ) − 2 q 2 = − q 2 2 + 6 q 2 − d q 2 ↓ ∂ π 2 ∂ q 2 = − 2 q 2 + 6 − d = 0 → q 2 = 6 − d 2 ↓ π 2 = ( 6 − d ) 2 4 \pi_2=q_2(8-(d+q_2))-2q_2=-q_2^2+6q_2-dq_2\\
\downarrow\\
\frac{\partial \pi_2}{\partial q_2}=-2q_2+6-d=0\rightarrow q_2=\frac{6-d}{2}\\
\downarrow\\
\pi_2=\frac{(6-d)^2}{4} π 2 = q 2 ( 8 − ( d + q 2 )) − 2 q 2 = − q 2 2 + 6 q 2 − d q 2 ↓ ∂ q 2 ∂ π 2 = − 2 q 2 + 6 − d = 0 → q 2 = 2 6 − d ↓ π 2 = 4 ( 6 − d ) 2
如果选择低水平合作
P V = [ ( 6 d − 2 d 2 ) , ( 6 d − 2 d 2 ) δ , ( 6 d − 2 d 2 ) δ 2 , … , ( 6 d − 2 d 2 ) δ n − 1 ] ↓ T P V = ( 6 d − 2 d 2 ) 1 1 − δ PV=[(6d-2d^2),(6d-2d^2)\delta,(6d-2d^2)\delta^2,\dots,(6d-2d^2)\delta^{n-1}]\\
\downarrow\\
TPV=(6d-2d^2)\frac{1}{1-\delta} P V = [( 6 d − 2 d 2 ) , ( 6 d − 2 d 2 ) δ , ( 6 d − 2 d 2 ) δ 2 , … , ( 6 d − 2 d 2 ) δ n − 1 ] ↓ TP V = ( 6 d − 2 d 2 ) 1 − δ 1 如果选择不合作
P V = [ ( 6 − d ) 2 4 , 4 δ , 4 δ 2 , … , 4 δ n − 1 ] ↓ T P V = ( 6 − d ) 2 4 + 4 δ 1 − δ PV=[\frac{(6-d)^2}{4},4\delta,4\delta^2,\dots,4\delta^{n-1}]\\
\downarrow\\
TPV=\frac{(6-d)^2}{4}+4\frac{\delta}{1-\delta} P V = [ 4 ( 6 − d ) 2 , 4 δ , 4 δ 2 , … , 4 δ n − 1 ] ↓ TP V = 4 ( 6 − d ) 2 + 4 1 − δ δ 如果合作的总现值大于不合作的总现值,选择合作
( 6 d − 2 d 2 ) 1 1 − δ > ( 6 − d ) 2 4 + 4 δ 1 − δ 6 d − 2 d 2 > 1 4 ( 36 + d 2 − 12 d ) ( 1 − δ ) + 4 δ 6 d − 2 d 2 > 9 − 9 δ + 1 4 d 2 − 1 4 d 2 δ − 3 d + 3 d δ + 4 δ 24 d − 8 d 2 > 36 − 36 δ + d 2 − d 2 δ − 12 d + 12 d δ + 16 δ 0 > ( 9 − δ ) d 2 + ( 12 δ − 36 ) d + ( 36 − 20 δ ) 0 > [ ( 9 − δ ) d + ( − 18 + 10 δ ) ] [ ( d + ( − 2 ) ] (6d-2d^2)\frac1{1-\delta}\gt\frac{(6-d)^2}{4}+4\frac{\delta}{1-\delta}\\
6d-2d^2\gt\frac{1}{4}(36+d^2-12d)(1-\delta)+4\delta\\
6d-2d^2\gt 9-9\delta+\frac14d^2-\frac14d^2\delta-3d+3d\delta+4\delta\\
24d-8d^2\gt36-36\delta+d^2-d^2\delta-12d+12d\delta+16\delta\\
0\gt (9-\delta) d^2+(12\delta-36)d+(36-20\delta)\\
0\gt[(9-\delta)d+(-18+10\delta)][(d+(-2)] ( 6 d − 2 d 2 ) 1 − δ 1 > 4 ( 6 − d ) 2 + 4 1 − δ δ 6 d − 2 d 2 > 4 1 ( 36 + d 2 − 12 d ) ( 1 − δ ) + 4 δ 6 d − 2 d 2 > 9 − 9 δ + 4 1 d 2 − 4 1 d 2 δ − 3 d + 3 d δ + 4 δ 24 d − 8 d 2 > 36 − 36 δ + d 2 − d 2 δ − 12 d + 12 d δ + 16 δ 0 > ( 9 − δ ) d 2 + ( 12 δ − 36 ) d + ( 36 − 20 δ ) 0 > [( 9 − δ ) d + ( − 18 + 10 δ )] [( d + ( − 2 )] 如果 ( 9 − δ ) d + ( 10 δ − 18 ) > 0 (9-\delta)d+(10\delta-18)\gt 0 ( 9 − δ ) d + ( 10 δ − 18 ) > 0
d > 18 − 10 δ 9 − δ = 90 − 10 δ − 90 + 18 9 − δ = 10 − 72 9 − δ ↓ 2 > 18 − 10 δ 9 − δ d\gt\frac{18-10\delta}{9-\delta}=\frac{90-10\delta-90+18}{9-\delta}=10-\frac{72}{9-\delta}\\
\downarrow\\
2\gt\frac{18-10\delta}{9-\delta}\\ d > 9 − δ 18 − 10 δ = 9 − δ 90 − 10 δ − 90 + 18 = 10 − 9 − δ 72 ↓ 2 > 9 − δ 18 − 10 δ 收益矩阵
[ 高 低 高 ( 4 , 4 ) ( 0 , 5 ) 低 ( 5 , 0 ) ( 1 , 1 ) ] \begin{bmatrix}
& 高 & 低 \\
高 & (4,4) & (0,5) \\
低 & (5,0) & (1,1) \\
\end{bmatrix} 高 低 高 ( 4 , 4 ) ( 5 , 0 ) 低 ( 0 , 5 ) ( 1 , 1 ) 选择合作
P V = [ 4 , 4 δ , 4 δ 2 , … , 4 δ n − 1 ] PV=[4,4\delta,4\delta^2,\dots,4\delta^{n-1}] P V = [ 4 , 4 δ , 4 δ 2 , … , 4 δ n − 1 ] V e = 4 1 − δ V_e=\frac{4}{1-\delta} V e = 1 − δ 4 选择不合作
P V = [ 5 , δ , δ 2 , … , δ n − 1 ] PV=[5,\delta,\delta^2,\dots,\delta^{n-1}] P V = [ 5 , δ , δ 2 , … , δ n − 1 ] V c = 5 + δ 1 − δ V_c=5+\frac{\delta}{1-\delta} V c = 5 + 1 − δ δ 如果要选择合作
4 1 − δ > 5 + δ 1 − δ 4 > 5 − 5 δ + δ δ > 1 4 \frac{4}{1-\delta}\gt 5+\frac{\delta}{1-\delta}\\
4\gt5-5\delta+\delta\\
\delta\gt\frac14 1 − δ 4 > 5 + 1 − δ δ 4 > 5 − 5 δ + δ δ > 4 1 甲 P P P C C C
乙 V H V_H V H V L V_L V L
graph
A[自然] -->|p好| B[甲]
A -->|1-p差| C[甲]
B -->|卖| D[乙]
C -->|卖(伪装)| E[乙]
C -->|不卖| F["(0,0)"]
D -->|买| G["(P,V_H-P)"]
D -->|不买| H["(0,0)"]
E -->|买| I["(P-C,V_L-P)"]
E -->|不买| J["(-C,0)"]
逆推归纳法
第三阶段 对乙
买的期望收益
p ( V H − P ) + ( 1 − p ) ( V L − P ) p(V_H-P)+(1-p) (V_L-P) p ( V H − P ) + ( 1 − p ) ( V L − P ) 不买的期望收益
p 0 + ( 1 − p ) 0 = 0 p0+(1-p)0=0 p 0 + ( 1 − p ) 0 = 0 如果要买
p V H − p P + V L − P − p V L + p P > 0 p V H + ( 1 − p ) V L > P pV_H-pP+V_L-P-pV_L+pP\gt0\\
pV_H+(1-p)V_L\gt P p V H − pP + V L − P − p V L + pP > 0 p V H + ( 1 − p ) V L > P 第二阶段 对甲
如果 P − C > 0 P-C\gt0 P − C > 0
代理的努力程度与工作结果关系不确定、且委托无法监督代理的努力程度
graph
A[委托] -->|雇佣| B[代理]
A -->|不雇佣| C["(R_o,W_o)"]
B -->|应聘| D[代理]
B -->|不应聘| E["(R_o,W_o)"]
D -->|努力| F[自然]
D -->|偷懒| G[自然]
F -->|p高| H["(R_H-W_H,W_H-e)"]
F -->|1-p低| I["(R_L-W_L,W_L-e)"]
G -->|q高| J["(R_H-W_H,W_H)"]
G -->|1-q低| K["(R_L-W_L,W_L)"]
逆推归纳法
第四阶段 自然决定不考虑
第三阶段 对代理
选择努力的期望收益
p ( W H − e ) + ( 1 − p ) ( W L − e ) p(W_H-e)+(1-p)(W_L-e) p ( W H − e ) + ( 1 − p ) ( W L − e ) 选择偷懒的期望收益
q W H + ( 1 − q ) W L qW_H+(1-q)W_L q W H + ( 1 − q ) W L 如果选择努力
p W H − p e + W L − e − p W L + p e > q W H + W L − q W L p W H − q W L > q W H − q W L + e ( p − q ) ( W H − W L ) > e W H − W L > e p − q pW_H-pe+W_L-e-pW_L+pe\gt qW_H+W_L-qW_L\\
pW_H-qW_L\gt qW_H-qWL+e\\
(p-q)(W_H-W_L)\gt e\\
W_H-W_L\gt\frac{e}{p-q} p W H − p e + W L − e − p W L + p e > q W H + W L − q W L p W H − q W L > q W H − q W L + e ( p − q ) ( W H − W L ) > e W H − W L > p − q e 第二阶段 对代理
选择应聘的期望收益
p ( W H − e ) + ( 1 − p ) ( W L − e ) p(W_H-e)+(1-p)(W_L-e) p ( W H − e ) + ( 1 − p ) ( W L − e ) 选择不应聘的期望收益
W o W_o W o 如果选择应聘
p W H + ( 1 − p ) W L > W o + e pW_H+(1-p) W_L\gt W_o+e p W H + ( 1 − p ) W L > W o + e 第一阶段 对委托
选择雇佣的期望收益
p ( R H − W H ) + ( 1 − p ) ( R L − W L ) p(R_H-W_H)+(1-p)(R_L-W_L) p ( R H − W H ) + ( 1 − p ) ( R L − W L ) 选择不雇佣的期望收益
R o R_o R o W ∗ W^* W ∗ 员工选择努力
graph LR
A["员工拿W^*"] -->|努力| B["员工拿W^*"]
B -->|努力| C
C -->|努力| D
P V = [ W ∗ − e , ( W ∗ − e ) δ , … , ( W ∗ − e ) δ n − 1 ] PV=[W^*-e,(W^*-e)\delta,\dots,(W^*-e)\delta^{n-1}] P V = [ W ∗ − e , ( W ∗ − e ) δ , … , ( W ∗ − e ) δ n − 1 ] T P V = ( W ∗ − e ) ( 1 − δ n ) 1 − δ = W ∗ − e 1 − δ TPV=\frac{(W^*-e)(1-\delta^n)}{1-\delta}=\frac{W^*-e}{1-\delta} TP V = 1 − δ ( W ∗ − e ) ( 1 − δ n ) = 1 − δ W ∗ − e 两阶段博弈
V e = W ∗ − e + V e δ → V e = W ∗ − e 1 − δ V_e=W^*-e+V_e\delta\rightarrow V_e=\frac{W^*-e}{1-\delta} V e = W ∗ − e + V e δ → V e = 1 − δ W ∗ − e 员工选择偷懒
graph LR
A[员工拿W^*] -->|偷懒| B
B[自然] -->|p高| C[员工拿W^*]
B -->|1-p低| D[员工拿W_o]
C -->|偷懒| E[自然]
E -->|p高| F[...]
E -->|1-p低| G[员工拿W^o]
V s = W ∗ + δ ( p V s + ( 1 − p ) W o 1 − δ ) V s = 1 1 − p δ ( W ∗ + ( 1 − p ) δ W o 1 − δ ) V_s=W^*+\delta(pV_s+(1-p)\frac{W_o}{1-\delta})\\
V_s=\frac{1}{1-p\delta}(W^*+(1-p)\delta\frac{W_o}{1-\delta}) V s = W ∗ + δ ( p V s + ( 1 − p ) 1 − δ W o ) V s = 1 − p δ 1 ( W ∗ + ( 1 − p ) δ 1 − δ W o ) 让员工选择努力
W ∗ − e 1 − δ > 1 1 − p δ ( W ∗ + ( 1 − p ) δ W o 1 − δ ) ( W ∗ − e ) ( 1 − p δ ) > W ∗ − δ W ∗ + δ W o − p δ W o W ∗ − e − p δ W ∗ + p e δ > W ∗ − δ W ∗ + δ W o − p δ W o W ∗ ( δ − p δ ) + W o ( p δ − δ ) > e ( 1 − p δ ) W ∗ − W o > e 1 − p δ δ − p δ W ∗ > W o + e 1 − p δ + δ − δ δ − p δ W ∗ > W o + e ( δ − p δ δ − p δ + 1 − δ δ − p δ ) W ∗ > W o + e + e 1 δ − 1 1 − p \frac{W^*-e}{1-\delta}\gt\frac{1}{1-p\delta}(W^*+(1-p)\delta\frac{W_o}{1-\delta})\\
(W^*-e)(1-p\delta)\gt W^*-\delta W^*+\delta W_o-p\delta W_o\\
W^*-e-p\delta W^*+pe\delta\gt W^*-\delta W^*+\delta W_o-p\delta W_o\\
W^*(\delta-p\delta)+W_o(p\delta-\delta)\gt e (1-p\delta)\\
W^*-W_o\gt e\frac{1-p\delta}{\delta-p\delta}\\
W^*\gt W_o+e\frac{1-p\delta+\delta-\delta}{\delta-p\delta}\\
W^*\gt W_o+e(\frac{\delta-p\delta}{\delta-p\delta}+\frac{1-\delta}{\delta-p\delta})\\
W^*\gt W_o+e+e\frac{\frac{1}{\delta}-1}{1-p} 1 − δ W ∗ − e > 1 − p δ 1 ( W ∗ + ( 1 − p ) δ 1 − δ W o ) ( W ∗ − e ) ( 1 − p δ ) > W ∗ − δ W ∗ + δ W o − p δ W o W ∗ − e − p δ W ∗ + p eδ > W ∗ − δ W ∗ + δ W o − p δ W o W ∗ ( δ − p δ ) + W o ( p δ − δ ) > e ( 1 − p δ ) W ∗ − W o > e δ − p δ 1 − p δ W ∗ > W o + e δ − p δ 1 − p δ + δ − δ W ∗ > W o + e ( δ − p δ δ − p δ + δ − p δ 1 − δ ) W ∗ > W o + e + e 1 − p δ 1 − 1
W o W_o W o e e e e 1 δ − 1 1 − p e\frac{\frac{1}{\delta}-1}{1-p} e 1 − p δ 1 − 1
努力成本大,补贴就大
δ \delta δ
p p p
直接机制:内心的估价
间接机制:付款额
说实话机制:说出内心的估价,说实话的直接机制
任一贝叶斯博弈的贝叶斯均衡都可由一说实话的直接机制来实现
例:甲有一画要卖,A、B 两人要买。甲想了解 A、B 对画的真实评价。
甲设计
A、B 各报价 x x x y y y
A 得画的概率 x = x x + y x=\frac{x}{x+y} x = x + y x y = y x + y y=\frac{y}{x+y} y = x + y y
A 得画付款 k x kx k x l y ly l y
设 A 的内心真实估价为 a a a x = t a x=ta x = t a
A 的期望收益
π A = x ( a − k x ) + ( 1 − x ) 0 = t a ( a − k t a ) = t a 2 − k t 2 a 2 ↓ ∂ π A ∂ t = a 2 − 2 k a 2 t = 0 ↓ t = 1 2 k \pi_A=x(a-kx)+(1-x)0=ta(a-kta)=ta^2-kt^2a^2\\
\downarrow\\
\frac{\partial \pi_A}{\partial t}=a^2-2ka^2t=0\\
\downarrow\\
t=\frac{1}{2k} π A = x ( a − k x ) + ( 1 − x ) 0 = t a ( a − k t a ) = t a 2 − k t 2 a 2 ↓ ∂ t ∂ π A = a 2 − 2 k a 2 t = 0 ↓ t = 2 k 1 甲要 A 说实话,也就是 t = 1 t=1 t = 1 k = 1 2 k=\frac12 k = 2 1