Python 代码
拉格朗日函数
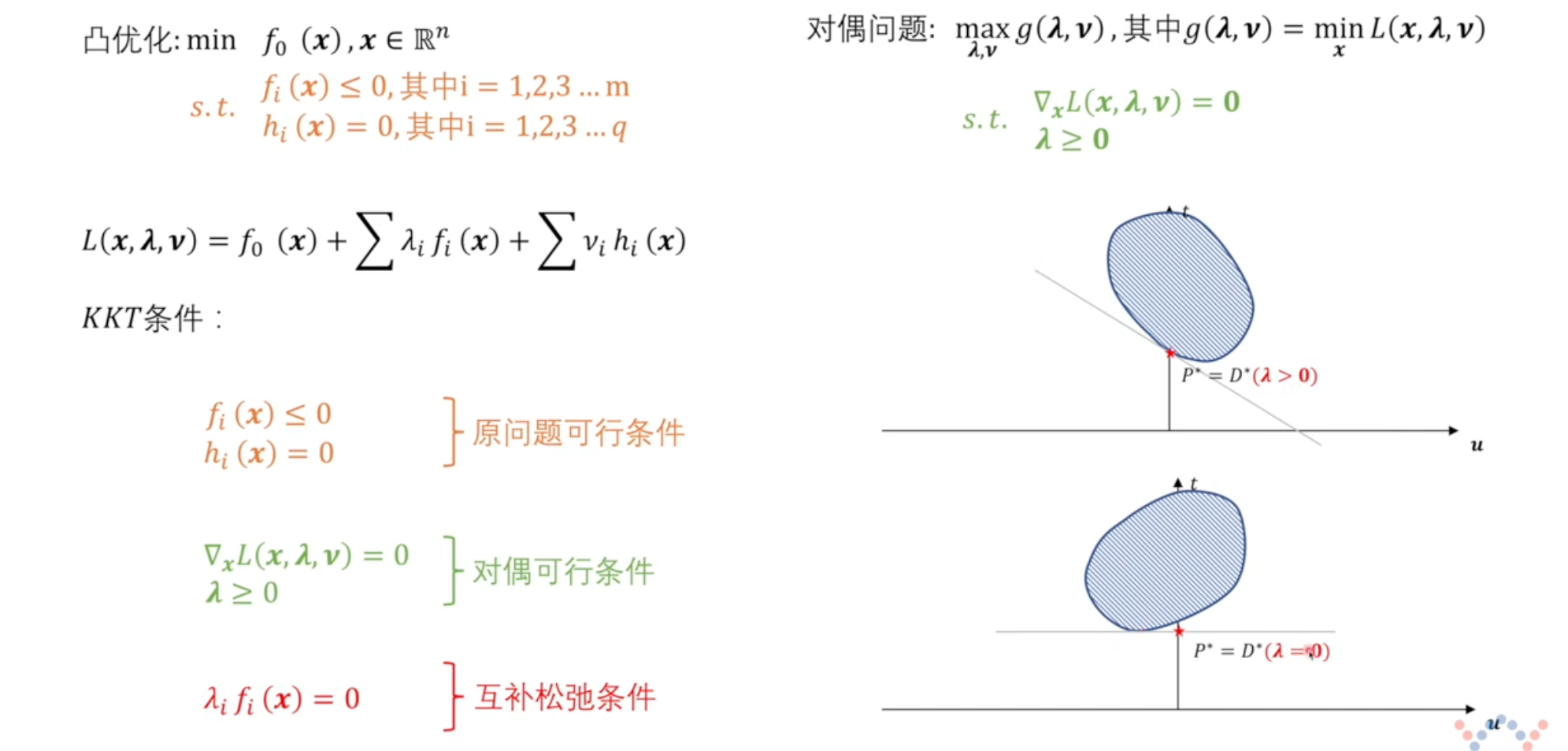
原问题
假设有一个在限定条件下需要求极值的问题,如下:
xminf(x),x∈Rns.t. gi(x)≤0,i=1,2,…,mhi(x)=0,i=1,2…,q
拉格朗日函数
L(x,λ,μ)=f(x)+∑λigi(x)+∑μihi(x)
转化为原问题的等价形式
xminλ,μmaxL(x,λ,μ)s.t. λ≥0
理解为什么原问题的拉格朗日函数形式等价于原问题?
x 在 L 中是可以取全域的(没有限制条件了,可以随便瞎取),L 只限制了 λ.
先考虑 maxλ,μL(x,λ,μ)
x不在可行域内→λ,μmaxL(x,λ,μ)=f(x)+∞+∞=∞x在可行域内→λ,μmaxL(x,λ,μ)=f(x)+0+0=f(x)↓xminλ,μmaxL(x,λ,μ)=xmin{f(x),∞}=xminf(x)
理解什么是互补松弛?
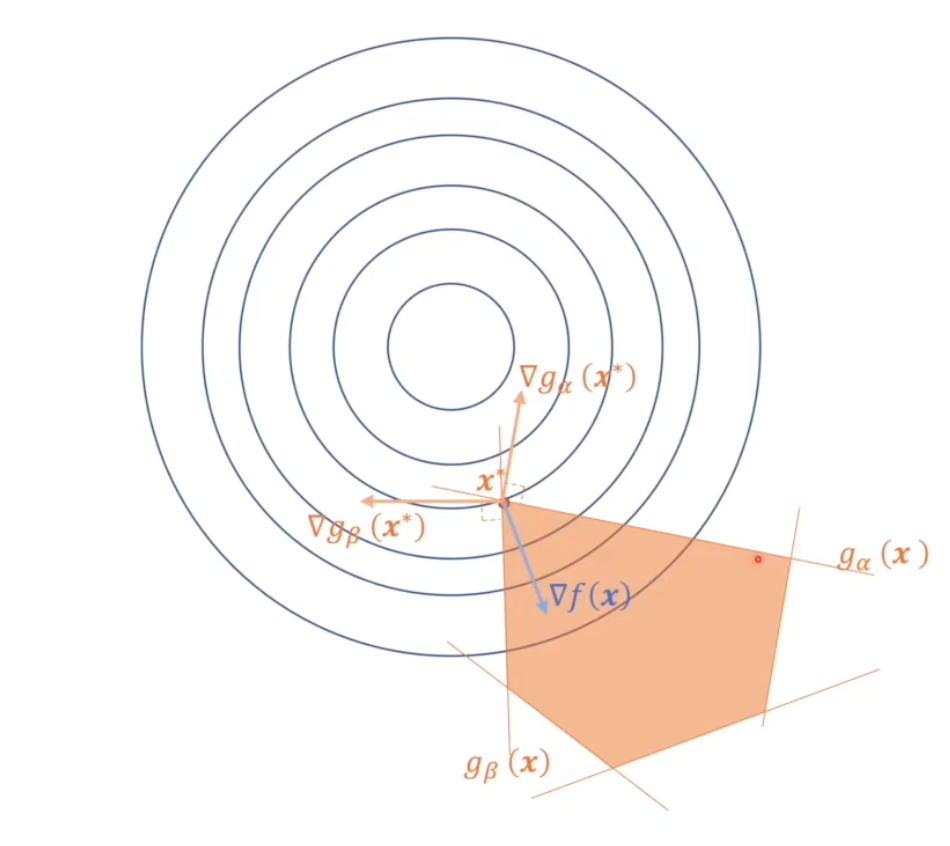
假设有五个不等式约束函数 gi(x),只有其中两个约束 gα 和 gβ 在求极值的时候用上了。因此其他约束函数的系数 λi=0,λα,λβ≥0. 通俗理解就是,约束函数用上了(紧致),则系数不等于 0(松弛),约束函数没用上(松弛),则系数等于 0(紧致).
互补松弛定理 One of KKT conditions
所有 λi≥0{λi=0,gi(x) 松弛λi>0,gi(x) 紧致
对偶函数
假设 g(λ,μ)=minxL(x,λ,μ),这个也被称为原问题的对偶函数
λ,μmaxg(λ,μ)→λ,μmaxxminL(x,λ,μ)s.t. λ≥0↓λ,μmaxg(λ,μ)s.t. ∇xL(x,λ,μ)=0λ≥0
理解什么是对偶问题?
对偶问题的特性:无论原问题是什么,换成对偶问题后都是一个凸问题
凸集 C 的定义:∀x1,x2∈C,0≤θ≤1→θx1+(1−θ)x2∈C
假设说找到一个 x∗=argminxL(x,λ,μ),则有
g(λ,μ)=f(x∗)+∑λigi(x∗)+∑μihi(x∗)
关于 λ 和 μ 的一阶线性的 g 函数确定的是一条直线(求最大值:凹函数)
总结
-
原问题
xminλ,μmaxL(x,λ,μ)s.t. λ≥0
这种形式的表达等价于
xminf(x)s.t. gi(x)≤0,i=1,2,…,mhi(x)=0,i=1,2,…,q
-
对偶问题
λ,μmaxg(λ,μ)=λ,μmaxxminL(x,λ,μ)s.t. λ≥0
-
比较二者
λ,μmaxL(x,λ,μ)≥L(x,λ,μ)≥xminL(x,λ,μ)↓A(x)=λ,μmaxL(x,λ,μ)≥L(x,λ,μ)≥xminL(x,λ,μ)=I(λ,μ)↓A(x)≥I(λ,μ)↓A(x)≥xminA(x)≥λ,μmaxI(λ,μ)=I(λ,μ)↓P∗=xminA(x)≥λ,μmaxI(λ,μ)=D∗
- P∗ 是原问题的解
- D∗ 是对偶问题的解
minf(x,y)s.t. y=g(x)
L(x,y,λ)=f(x,y)+λ(y−g(x))↓∇L(x,y,λ)=0↓{∂x∂f(x,y)+λ∂x∂(y−g(x))=0∂y∂f(x,y)+λ∂y∂(y−g(x))=0
minf(x),x∈Rns.t. gi(x)=aiT⋅x+bi≤0,i=1,2,…,m,ai∈Rn,bi∈R
L(x,λ)=f(x)+i=1∑mλigi(x)↓∇L(x,λ)=0↓∇f(x)+i=1∑mλi∇gi(x)=0
Slater 条件
Slater 条件是强对偶问题的充分条件(只要满足 Slater 条件,就是强对偶;强对偶问题不一定满足 Slater 条件)
Slater 条件的定义:存在一个点 x∈relint D,使得 gi(x)<0,其中 i=1,2,…,m,Ax=b
relint D 表示可行域 D 的相对内部
如何理解这个鬼定义?
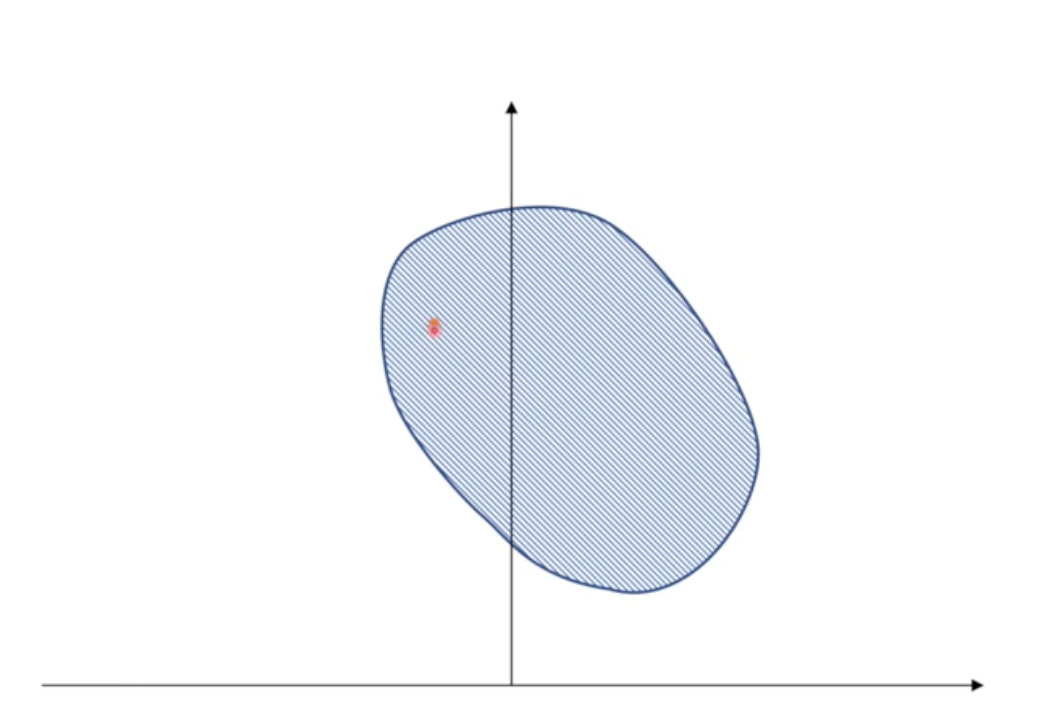
这个定义域的左半边至少存在一个点
KKT 条件
KKT 条件是强对偶问题的必要条件(只要是强对偶问题,一定满足 KKT 条件)
KKT 条件的定义
Reference