这学期我学习了三门与数学有关的课程,分别是线性代数、微分方程和选修课探寻数学的理与美。在探寻数学的理与美课上,我从不同老师的讲课中从另一个角度重新审视了数学之美以及它的用途。对于我而言,微分方程的用途总是十分直观的,而与之相比,线性代数则显得更加偏教科书化。尽管我学习了线性代数的各种基本知识与定理,但我仍然对其中的各种概念如特征值、零空间等缺乏立体的审视,因此我在课外阅读了许多将线性代数与几何相结合的资料,对知识的巩固加深了理解。在其中,令我印象最深的就是奇异值分解以及它在压缩图像上的应用。
由于本学期的课程上教授还未教授奇异值分解的内容,对于奇异值分解相关知识的学习我几乎都是从不同的电子书以及一个名为“线代启示录”的台湾博客中了解到。一开始我先是粗略地浏览了很多资料,了解到奇异值分解的目的是为了把一个m × n m\times n m × n A v i = σ i u i Av_i=\sigma_iu_i A v i = σ i u i A A A m × n m\times n m × n σ i \sigma_i σ i
关于这个式子是如何来的,我主要参考了“线代启示录”的作者的思路。值得一提的是,从这个博客里我意外地发现在台湾对矩阵的行与列的定义与我们居然是相反的。台湾文章中的行是我们所指的列,而列是我们所指的行,这点导致了我在阅读相关文章的时候产生了不小的误解,幸而作者标记了英文的 row 与 col 的注释,这大大降低了我阅读时的难度。为了得到A v i = σ i u i Av_i=\sigma_iu_i A v i = σ i u i A T A A^TA A T A A A T AA^T A A T v i v_i v i A T A A^TA A T A A A A A v i = σ i u i Av_i=\sigma_iu_i A v i = σ i u i u i u_i u i v i v_i v i u i u_i u i A v i = σ i u i Av_i=\sigma_iu_i A v i = σ i u i
其中最令我感到神奇的是在处理u i u_i u i
对于矩阵A T A n × n A^TA_{n\times n} A T A n × n A T A A^TA A T A A T A v i = σ i 2 v i , i = 1 , 2 , … , n A^TAv_i=\sigma_i^2v_i,\ i=1,2,\ldots,n A T A v i = σ i 2 v i , i = 1 , 2 , … , n
A T A [ v 1 : v 2 : ⋮ : v n ] = [ A T A v 1 : A T A v 2 : ⋯ : A T A v n ] = [ σ 1 2 v 1 : σ 2 2 v 2 : ⋯ : σ n 2 v n ] = [ v 1 : v 2 : ⋯ : v n ] [ σ 1 2 0 ⋯ 0 0 σ 2 2 ⋯ 0 ⋮ ⋮ ⋱ ⋮ 0 0 ⋯ σ n 2 ] \begin{aligned}
A^TA[v_1:v_2:\vdots:v_n]=&[A^TAv_1:A^TAv_2:\dots:A^TAv_n]\\=& [\sigma_1^2v_1:\sigma_2^2v_2:\dots:\sigma_n^2v_n] \\=&[v_1:v_2:\dots:v_n] \left[ \begin{matrix}\sigma_1^2&0&\cdots&0 \\ 0&\sigma_2^2&\cdots&0\\\vdots&\vdots&\ddots&\vdots\\0&0&\cdots&\sigma_n^2\end{matrix} \right]
\end{aligned} A T A [ v 1 : v 2 : ⋮ : v n ] = = = [ A T A v 1 : A T A v 2 : ⋯ : A T A v n ] [ σ 1 2 v 1 : σ 2 2 v 2 : ⋯ : σ n 2 v n ] [ v 1 : v 2 : ⋯ : v n ] σ 1 2 0 ⋮ 0 0 σ 2 2 ⋮ 0 ⋯ ⋯ ⋱ ⋯ 0 0 ⋮ σ n 2 令矩阵V V V [ v 1 : v 2 : ⋯ : v n ] [v_1:v_2:\dots:v_n] [ v 1 : v 2 : ⋯ : v n ]
A T A = V [ σ 1 2 0 ⋯ 0 0 σ 2 2 ⋯ 0 ⋮ ⋮ ⋱ ⋮ 0 0 ⋯ σ n 2 ] V − 1 = V [ σ 1 2 0 ⋯ 0 0 σ 2 2 ⋯ 0 ⋮ ⋮ ⋱ ⋮ 0 0 ⋯ σ n 2 ] V T A^TA=V\left[ \begin{matrix} \sigma_1^2&0&\cdots&0 \\ 0&\sigma_2^2&\cdots&0\\\vdots&\vdots&\ddots&\vdots\\0&0&\cdots&\sigma_n^2\end{matrix} \right]V^{-1}=V\left[ \begin{matrix} \sigma_1^2&0&\cdots&0 \\ 0&\sigma_2^2&\cdots&0\\\vdots&\vdots&\ddots&\vdots\\0&0&\cdots&\sigma_n^2\end{matrix} \right]V^{T} A T A = V σ 1 2 0 ⋮ 0 0 σ 2 2 ⋮ 0 ⋯ ⋯ ⋱ ⋯ 0 0 ⋮ σ n 2 V − 1 = V σ 1 2 0 ⋮ 0 0 σ 2 2 ⋮ 0 ⋯ ⋯ ⋱ ⋯ 0 0 ⋮ σ n 2 V T 假设 r a n k ( A T A ) = r a n k ( [ σ 1 2 0 ⋯ 0 0 σ 2 2 ⋯ 0 ⋮ ⋮ ⋱ ⋮ 0 0 ⋯ σ n 2 ] ) = r rank(A^TA)=rank(\begin{bmatrix} \sigma_1^2&0&\cdots&0 \\ 0&\sigma_2^2&\cdots&0\\\vdots&\vdots&\ddots&\vdots\\0&0&\cdots&\sigma_n^2\end{bmatrix})=r r ank ( A T A ) = r ank ( σ 1 2 0 ⋮ 0 0 σ 2 2 ⋮ 0 ⋯ ⋯ ⋱ ⋯ 0 0 ⋮ σ n 2 ) = r
让 σ 1 ≥ σ 2 ≥ ⋯ ≥ σ r > 0 , σ r + 1 = σ r + 2 = ⋯ = σ n = 0 \sigma_1\ge\sigma_2\ge\dots\ge\sigma_r\gt0,\ \sigma_{r+1}=\sigma_{r+2}=\dots=\sigma_n=0 σ 1 ≥ σ 2 ≥ ⋯ ≥ σ r > 0 , σ r + 1 = σ r + 2 = ⋯ = σ n = 0
∵ A T A v i = σ i 2 v i \because\ A^TAv_i=\sigma_i^2v_i\\ ∵ A T A v i = σ i 2 v i ∴ v i T A T A v i = v i T σ i 2 v i = σ i 2 ∥ A v i ∥ 2 = σ i 2 \therefore\ v_i^TA^TAv_i=v_i^T\sigma_i^2v_i=\sigma_i^2\\
\| Av_i \|^2=\sigma_i^2 ∴ v i T A T A v i = v i T σ i 2 v i = σ i 2 ∥ A v i ∥ 2 = σ i 2 ∵ σ i = 0 , i = r + 1 , r + 2 , … , n \because\ \sigma_i=0,\ i=r+1,r+2,\dots,n \\ ∵ σ i = 0 , i = r + 1 , r + 2 , … , n ∴ A v i = 0 , i = r + 1 , r + 2 , … , n ⇒ n u l l ( A ) = s p a n ( v r + 1 , v r + 2 , … , v n ) = r o w ( A ) ⊥ \therefore\ Av_i=0,\ i=r+1,r+2,\dots,n\\\Rightarrow null(A)=span(v_{r+1},v_{r+2},\ldots,v_n)=row(A)^{\perp} ∴ A v i = 0 , i = r + 1 , r + 2 , … , n ⇒ n u ll ( A ) = s p an ( v r + 1 , v r + 2 , … , v n ) = ro w ( A ) ⊥ ∵ s p a n ( v 1 , v 2 , … , v r ) ⊥ s p a n ( v r + 1 , v r + 2 , … , v n ) = r o w ( A ) ⊥ \because\ span(v_1,v_2,\ldots,v_r)\perp span(v_{r+1},v_{r+2},\ldots,v_n)=row(A)^\perp\\ ∵ s p an ( v 1 , v 2 , … , v r ) ⊥ s p an ( v r + 1 , v r + 2 , … , v n ) = ro w ( A ) ⊥ ⇒ r o w ( A ) = s p a n ( v 1 , v 2 , … , v r ) \Rightarrow \ row(A)=span(v_1,v_2,\ldots,v_r) ⇒ ro w ( A ) = s p an ( v 1 , v 2 , … , v r ) 接着对A A m × m T AA^T_{m\times m} A A m × m T
假设对于 A A m × m T AA^T_{m\times m} A A m × m T u i = A v i σ i , i = 1 , 2 , … , r u_i=\frac{Av_i}{\sigma_i}, i=1,2,\ldots,r u i = σ i A v i , i = 1 , 2 , … , r
u i ⋅ u y = u i T u y = ( A v i ) T σ i A v j σ j = v i T A T σ i A v j σ j = v i T ( A T A v j ) σ i σ j = v i T ( σ j 2 v j ) σ i σ j = σ j 2 σ i σ j v i T v j = { 0 , f o r i ≠ j 1 , f o r i = j \begin{aligned}u_i\cdot u_y=u_i^Tu_y = &\frac{(Av_i)^T}{\sigma_i}\frac{Av_j}{\sigma_j} \\=& \frac{v_i^TA^T}{\sigma_i}\frac{Av_j}{\sigma_j}=\frac{v_i^T(A^TAv_j)}{\sigma_i\sigma_j}\\=&\frac{v_i^T(\sigma_j^2v_j)}{\sigma_i\sigma_j}=\frac{\sigma_j^2}{\sigma_i\sigma_j}v_i^Tv_j \\=&\left\{\begin{aligned} &0,&for\ i\ne j\\&1,&for\ i=j\end{aligned} \right.\end{aligned} u i ⋅ u y = u i T u y = = = = σ i ( A v i ) T σ j A v j σ i v i T A T σ j A v j = σ i σ j v i T ( A T A v j ) σ i σ j v i T ( σ j 2 v j ) = σ i σ j σ j 2 v i T v j { 0 , 1 , f or i = j f or i = j r o w ( A T ) = c o l ( A ) = s p a n ( u 1 , u 2 , … , u r ) n u l l ( A T ) = s p a n ( u r + 1 , u r + 2 , … , u m ) row(A^T)=col(A)=span(u_1,u_2,\ldots,u_r)\\null(A^T)=span(u_{r+1},u_{r+2},\ldots,u_m) ro w ( A T ) = co l ( A ) = s p an ( u 1 , u 2 , … , u r ) n u ll ( A T ) = s p an ( u r + 1 , u r + 2 , … , u m ) 也由此,我明白了在奇异值分解中每个符号所代表的意义。重新审视A v i = σ i u i Av_i=\sigma_iu_i A v i = σ i u i σ \sigma σ
假设矩阵 A m × n A_{m\times n} A m × n r a n k ( A ) = r rank(A )=r r ank ( A ) = r A = U Σ V T A=U\Sigma V^T A = U Σ V T
U m × m = [ u 1 : u 2 : … : u m ] U_{m\times m}=[u_1:u_2:\ldots:u_m] U m × m = [ u 1 : u 2 : … : u m ] Σ m × n = [ σ 1 0 0 0 ⋯ 0 0 ⋱ 0 ⋮ ⋯ 0 0 0 σ r 0 ⋯ 0 0 ⋯ 0 0 ⋯ 0 ⋮ ⋱ ⋮ ⋮ ⋱ ⋮ 0 ⋯ 0 0 ⋯ 0 ] \Sigma_{m\times n}=\begin{bmatrix} \sigma_{1} & 0 & 0 & 0 &\cdots &0\\ 0 & \ddots & 0 & \vdots & \cdots & 0\\ 0 & 0 & \sigma_{r} & 0 &\cdots & 0\\ 0 & \cdots & 0 & 0 & \cdots &0\\ \vdots&\ddots&\vdots&\vdots&\ddots&\vdots\\0 & \cdots & 0 & 0 & \cdots & 0 \end{bmatrix} Σ m × n = σ 1 0 0 0 ⋮ 0 0 ⋱ 0 ⋯ ⋱ ⋯ 0 0 σ r 0 ⋮ 0 0 ⋮ 0 0 ⋮ 0 ⋯ ⋯ ⋯ ⋯ ⋱ ⋯ 0 0 0 0 ⋮ 0 V n × n = [ v 1 : v 2 : … : v n ] V_{n\times n}=[v_1:v_2:\ldots:v_n] V n × n = [ v 1 : v 2 : … : v n ] A = [ u 1 : u 2 : … : u m ] [ σ 1 0 0 0 ⋯ 0 0 ⋱ 0 ⋮ ⋯ 0 0 0 σ r 0 ⋯ 0 0 ⋯ 0 0 ⋯ 0 ⋮ ⋱ ⋮ ⋮ ⋱ ⋮ 0 ⋯ 0 0 ⋯ 0 ] [ v 1 T v 2 T ⋮ v n T ] = [ σ 1 u 1 : σ 2 u 2 : … : σ r u r : 0 : … : 0 ] [ v 1 T v 2 T ⋮ v n T ] = ∑ i = 1 r σ i u i v i T \begin{aligned}A=&[u_1:u_2:\ldots:u_m]\begin{bmatrix} \sigma_{1} & 0 & 0 & 0 &\cdots &0\\ 0 & \ddots & 0 & \vdots & \cdots & 0\\ 0 & 0 & \sigma_{r} & 0 &\cdots & 0\\ 0 & \cdots & 0 & 0 & \cdots &0\\ \vdots&\ddots&\vdots&\vdots&\ddots&\vdots\\0 & \cdots & 0 & 0 & \cdots & 0 \end{bmatrix}\begin{bmatrix}v_1^T\\v_2^T\\\vdots \\v_n^T\end{bmatrix}\\=&[\sigma_1u_1:\sigma_2u_2:\ldots:\sigma_ru_r:0:\ldots:0]\begin{bmatrix}v_1^T\\v_2^T\\\vdots \\v_n^T\end{bmatrix}\\=&\sum_{i=1}^r\sigma_iu_iv_i^T\end{aligned} A = = = [ u 1 : u 2 : … : u m ] σ 1 0 0 0 ⋮ 0 0 ⋱ 0 ⋯ ⋱ ⋯ 0 0 σ r 0 ⋮ 0 0 ⋮ 0 0 ⋮ 0 ⋯ ⋯ ⋯ ⋯ ⋱ ⋯ 0 0 0 0 ⋮ 0 v 1 T v 2 T ⋮ v n T [ σ 1 u 1 : σ 2 u 2 : … : σ r u r : 0 : … : 0 ] v 1 T v 2 T ⋮ v n T i = 1 ∑ r σ i u i v i T 学到了这个地方,我已经对奇异值分解具有初步的了解了。在浏览不同教材与网站的过程中,我的余光总是看到“图片压缩”这个词。一开始我并想不到这个式子能和压缩产生什么关系,但是反复盯着奇异值分解的标准形式A = ∑ i = 1 r σ i u i v i T A=\sum_{i=1}^r\sigma_iu_iv_i^T A = ∑ i = 1 r σ i u i v i T A A A A A A A A A
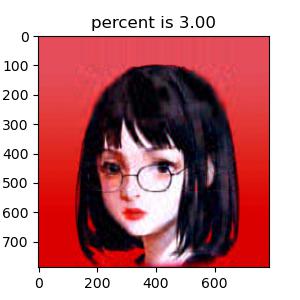
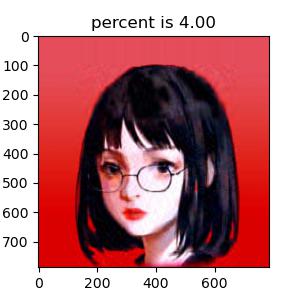
我选择了我的头像(如图)作为试验的对象,并使用了两个 Python 环境中的开源模块 Numpy 和 Matplotlib 来计算奇异值分解与读取图片。首先我便遇到了读取图片的困难。由于图片是彩色的,其导入到计算机的矩阵并不是一个二维矩阵,而是类似与( m , n , 3 ) (m,n,3) ( m , n , 3 )
import numpy as np
import matplotlib.pyplot as plt
sample = plt.imread("sample.jpg" )
sample = np.array(sample)
m, n = sample[:, :, 0 ].shape
r = sample[:, :, 0 ]
g = sample[:, :, 1 ]
b = sample[:, :, 2 ]
fig, ax = plt.subplots(1 , 3 )
ax[0 ].imshow(r)
ax[0 ].set_title('R channel' )
ax[1 ].imshow(g)
ax[1 ].set_title('G channel' )
ax[2 ].imshow(b)
ax[2 ].set_title('B channel' )
plt.show()
def SVD_compression (channel, p ):
U, sig, V_T = np.linalg.svd(channel)
newChannel = np.zeros((m, n))
for i in range (len (sig)):
newChannel += sig[i] * (U[:, i].reshape(m, 1 )@V_T[i, :].reshape(1 , n))
if float (i) / len (sig) > p:
newChannel[newChannel < 0 ] = 0
newChannel[newChannel > 255 ] = 255
break
return newChannel.astype('i2' )
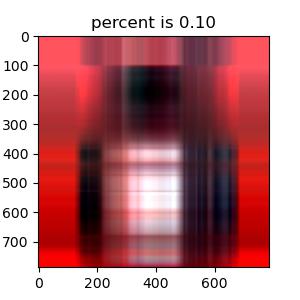
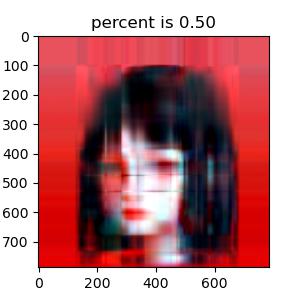
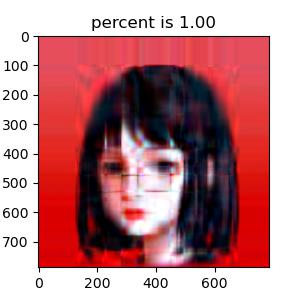
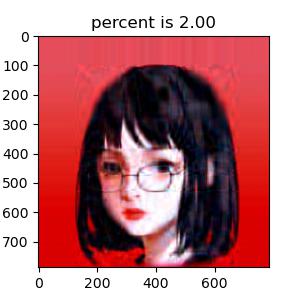
说到最重要的奇异值分解部分,不得不感谢 Numpy 模块 linalg 下自带的 svd 函数,使我省去了最繁琐的过程。为了清晰对比出我保留不同数量σ \sigma σ σ \sigma σ σ \sigma σ